Mašinų mokymasis yra šaka Dirbtinis intelektas kuri orientuota į modelių ir algoritmų kūrimą, kurie leidžia kompiuteriams mokytis iš duomenų ir tobulėti iš ankstesnės patirties, nebūdami aiškiai užprogramuoti kiekvienai užduočiai. Paprastais žodžiais tariant, ML moko sistemas mąstyti ir suprasti kaip žmones, mokantis iš duomenų.
Šiame straipsnyje mes išnagrinėsime įvairius tipai mašininio mokymosi algoritmai kurie yra svarbūs būsimiems reikalavimams. Mašininis mokymasis paprastai yra mokymo sistema, skirta mokytis iš ankstesnės patirties ir laikui bėgant pagerinti našumą. Mašininis mokymasis padeda numatyti didžiulius duomenų kiekius. Tai padeda pasiekti greitus ir tikslius rezultatus, kad gautumėte pelningų galimybių.
Mašininio mokymosi tipai
Yra keletas mašininio mokymosi tipų, kurių kiekvienas turi specialių savybių ir taikomųjų programų. Kai kurie pagrindiniai mašininio mokymosi algoritmų tipai yra tokie:
- Prižiūrimas mašininis mokymasis
- Neprižiūrimas mašininis mokymasis
- Pusiau prižiūrimas mašininis mokymasis
- Sustiprinimo mokymasis
Mašininio mokymosi tipai
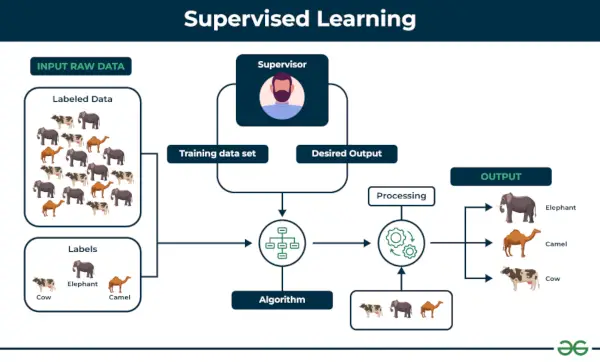
1. Prižiūrimas mašininis mokymasis
Prižiūrimas mokymasis apibrėžiamas kaip tada, kai modelis apmokomas a Pažymėtas duomenų rinkinys . Pažymėti duomenų rinkiniai turi ir įvesties, ir išvesties parametrus. Į Prižiūrimas mokymasis algoritmai išmoksta susieti taškus tarp įėjimų ir teisingų išėjimų. Jame pažymėti mokymo ir patvirtinimo duomenų rinkiniai.
Prižiūrimas mokymasis
Supraskime tai pavyzdžio pagalba.
Pavyzdys: Apsvarstykite scenarijų, kai turite sukurti vaizdo klasifikatorių, kad atskirtumėte kates ir šunis. Jei pateiksite šunų ir kačių pažymėtų vaizdų duomenų rinkinius pagal algoritmą, aparatas išmoks klasifikuoti šunį ar katę pagal šiuos paženklintus vaizdus. Kai įvesime naujus šuns ar katės vaizdus, kurių jis dar niekada nematė, jis naudos išmoktus algoritmus ir numatys, ar tai šuo, ar katė. Štai taip prižiūrimas mokymasis veikia, o tai ypač vaizdų klasifikacija.
java įterpimo rūšiavimas
Toliau paminėtos dvi pagrindinės prižiūrimo mokymosi kategorijos:
- klasifikacija
- Regresija
klasifikacija
klasifikacija užsiima numatymu kategoriškas tiksliniai kintamieji, kurie reiškia atskiras klases arba etiketes. Pavyzdžiui, el. laiškų klasifikavimas kaip šlamštas ar ne šlamštas arba numatymas, ar pacientas turi didelę širdies ligų riziką. Klasifikavimo algoritmai išmoksta susieti įvesties funkcijas vienai iš iš anksto nustatytų klasių.
Štai keletas klasifikavimo algoritmų:
- Logistinė regresija
- Palaikykite vektorinę mašiną
- Atsitiktinis miškas
- Sprendimų medis
- K-Artimiausi kaimynai (KNN)
- Naivus Bayesas
Regresija
Regresija , kita vertus, susijęs su numatymu tęstinis tikslinius kintamuosius, kurie reiškia skaitines reikšmes. Pavyzdžiui, namo kainos prognozavimas pagal jo dydį, vietą ir patogumus arba produkto pardavimo prognozavimas. Regresijos algoritmai išmoksta susieti įvesties ypatybes su nuolatine skaitine verte.
Štai keletas regresijos algoritmų:
- Tiesinė regresija
- Polinominė regresija
- Ridžo regresija
- Lasso regresija
- Sprendimų medis
- Atsitiktinis miškas
Prižiūrimo mašininio mokymosi privalumai
- Prižiūrimas mokymasis modeliai gali turėti didelį tikslumą, nes jie yra mokomi pažymėti duomenys .
- Prižiūrimų mokymosi modelių sprendimų priėmimo procesas dažnai yra interpretuojamas.
- Jis dažnai gali būti naudojamas iš anksto paruoštuose modeliuose, todėl sutaupoma laiko ir išteklių kuriant naujus modelius nuo nulio.
Prižiūrimo mašininio mokymosi trūkumai
- Ji turi apribojimų žinant modelius ir gali kovoti su nematomais ar netikėtais modeliais, kurių nėra mokymo duomenyse.
- Tai gali užtrukti ir brangiai kainuoti, nes nuo jo priklauso pažymėtas tik duomenys.
- Tai gali lemti prastus apibendrinimus remiantis naujais duomenimis.
Prižiūrėto mokymosi programos
Prižiūrimas mokymasis naudojamas įvairiose programose, įskaitant:
- Vaizdo klasifikacija : atpažinkite objektus, veidus ir kitas vaizdų savybes.
- Natūralios kalbos apdorojimas: Iš teksto ištraukite informaciją, pvz., jausmus, esybes ir ryšius.
- Kalbos atpažinimas : konvertuoti šnekamąją kalbą į tekstą.
- Rekomendavimo sistemos : pateikite asmenines rekomendacijas naudotojams.
- Nuspėjamoji analizė : Numatykite rezultatus, pvz., pardavimą, klientų atsitraukimą ir akcijų kainas.
- Medicininė diagnozė : aptikti ligas ir kitas sveikatos sąlygas.
- Sukčiavimo aptikimas : nustatykite nesąžiningus sandorius.
- Autonominės transporto priemonės : atpažinti ir reaguoti į aplinkos objektus.
- El. pašto šiukšlių aptikimas : klasifikuokite el. laiškus kaip šlamštą ar ne.
- Kokybės kontrolė gamyboje : Patikrinkite, ar gaminiuose nėra defektų.
- Kredito įvertinimas : Įvertinkite riziką, kad paskolos gavėjas nesumokės paskolos.
- Žaidimai : atpažinkite veikėjus, analizuokite žaidėjų elgesį ir kurkite NPC.
- Pagalba klientams : automatizuokite klientų aptarnavimo užduotis.
- Orų prognozavimas : Numatykite temperatūrą, kritulius ir kitus meteorologinius parametrus.
- Sporto analitika : analizuokite žaidėjo rezultatus, prognozuokite žaidimus ir optimizuokite strategijas.
2. Neprižiūrimas mašininis mokymasis
Mokymasis be priežiūros Neprižiūrimas mokymasis yra mašininio mokymosi technikos tipas, kai algoritmas atranda modelius ir ryšius naudodamas nepažymėtus duomenis. Skirtingai nei prižiūrimas mokymasis, neprižiūrimas mokymasis neapima algoritmo su pažymėtais tiksliniais rezultatais. Pagrindinis neprižiūrimo mokymosi tikslas dažnai yra atrasti paslėptus šablonus, panašumus ar grupes duomenų viduje, kuriuos vėliau galima naudoti įvairiems tikslams, pavyzdžiui, duomenų tyrinėjimui, vizualizavimui, matmenų mažinimui ir kt.
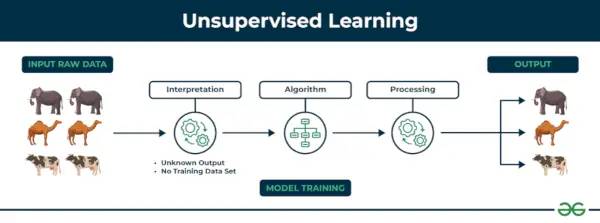
Mokymasis be priežiūros
Supraskime tai pavyzdžio pagalba.
Pavyzdys: Apsvarstykite, kad turite duomenų rinkinį, kuriame yra informacijos apie pirkinius, kuriuos įsigijote parduotuvėje. Naudodamas grupes, algoritmas gali sugrupuoti tą patį pirkimo elgesį tarp jūsų ir kitų klientų, o tai atskleidžia potencialius klientus be iš anksto nustatytų etikečių. Tokio tipo informacija gali padėti įmonėms pritraukti tikslinių klientų ir nustatyti pašalinius dalykus.
Toliau paminėtos dvi pagrindinės neprižiūrimo mokymosi kategorijos:
- Klasterizavimas
- asociacija
Klasterizavimas
Klasterizavimas yra duomenų taškų grupavimo į grupes procesas pagal jų panašumą. Šis metodas yra naudingas norint nustatyti duomenų šablonus ir ryšius, nereikalaujant pažymėtų pavyzdžių.
Štai keletas grupavimo algoritmų:
- K-Means klasterizacijos algoritmas
- Vidutinio poslinkio algoritmas
- DBSCAN algoritmas
- Pagrindinių komponentų analizė
- Nepriklausomų komponentų analizė
asociacija
Asociacijos taisyklė išmokti ing yra ryšių tarp duomenų rinkinio elementų nustatymo metodas. Jis identifikuoja taisykles, kurios nurodo vieno elemento buvimą, reiškia kito elemento buvimą su tam tikra tikimybe.
Štai keletas asociacijos taisyklių mokymosi algoritmų:
- Apriori algoritmas
- Švytėjimas
- FP augimo algoritmas
Neprižiūrimo mašininio mokymosi privalumai
- Tai padeda atrasti paslėptus šablonus ir įvairius ryšius tarp duomenų.
- Naudojamas tokioms užduotims kaip klientų segmentavimas, anomalijų aptikimas, ir duomenų tyrinėjimas .
- Tai nereikalauja žymėtų duomenų ir sumažina duomenų ženklinimo pastangas.
Neprižiūrimo mašininio mokymosi trūkumai
- Nenaudojant etikečių gali būti sunku numatyti modelio produkcijos kokybę.
- Klasterio interpretacija gali būti neaiški ir neturėti prasmingų interpretacijų.
- Jame yra tokios technikos kaip automatiniai kodavimo įrenginiai ir matmenų sumažinimas kuriuos galima naudoti norint iš neapdorotų duomenų išgauti reikšmingas funkcijas.
Neprižiūrimo mokymosi taikymai
Štai keletas bendrų neprižiūrimo mokymosi programų:
bash nuo 1 iki 10
- Klasterizavimas : sugrupuokite panašius duomenų taškus į grupes.
- Anomalijų aptikimas : nustatykite duomenų nukrypimus arba anomalijas.
- Matmenų mažinimas : sumažinkite duomenų matmenis, išsaugodami pagrindinę informaciją.
- Rekomendavimo sistemos : siūlykite naudotojams produktus, filmus ar turinį pagal jų istorinę elgseną ar nuostatas.
- Temos modeliavimas : atraskite paslėptas temas dokumentų rinkinyje.
- Tankio įvertinimas : Įvertinkite duomenų tikimybės tankio funkciją.
- Vaizdo ir vaizdo glaudinimas : sumažinkite daugialypės terpės turiniui reikalingą saugyklos kiekį.
- Išankstinis duomenų apdorojimas : Pagalba atliekant išankstinio duomenų apdorojimo užduotis, pvz., duomenų valymą, trūkstamų reikšmių priskyrimą ir duomenų mastelio keitimą.
- Rinkos krepšelio analizė : atraskite produktų asociacijas.
- Genominių duomenų analizė : identifikuokite modelius arba sugrupuokite genus su panašiais ekspresijos profiliais.
- Vaizdo segmentavimas : segmentuokite vaizdus į reikšmingus regionus.
- Bendruomenės aptikimas socialiniuose tinkluose : nustatykite bendruomenes ar asmenų grupes, turinčias panašių interesų ar ryšių.
- Klientų elgesio analizė : atraskite modelius ir įžvalgas, kad gautumėte geresnės rinkodaros ir produktų rekomendacijų.
- Turinio rekomendacija : klasifikuokite ir pažymėkite turinį, kad naudotojams būtų lengviau rekomenduoti panašius elementus.
- Tiriamoji duomenų analizė (EDA) : tyrinėkite duomenis ir gaukite įžvalgų prieš apibrėždami konkrečias užduotis.
3. Pusiau prižiūrimas mokymasis
Pusiau prižiūrimas mokymasis yra mašininio mokymosi algoritmas, veikiantis tarp prižiūrimas ir neprižiūrimas mokosi, todėl naudoja abu paženklintas ir nepažymėtas duomenis. Tai ypač naudinga, kai pažymėtų duomenų gavimas yra brangus, atima daug laiko arba reikalauja daug išteklių. Šis metodas yra naudingas, kai duomenų rinkinys yra brangus ir užima daug laiko. Iš dalies prižiūrimas mokymasis pasirenkamas, kai pažymėtiems duomenims reikia įgūdžių ir atitinkamų išteklių, kad būtų galima mokyti ar mokytis iš jų.
Mes naudojame šiuos metodus, kai dirbame su duomenimis, kurie yra šiek tiek pažymėti, o likusi didelė jų dalis yra nepažymėta. Galime naudoti neprižiūrimus metodus, kad galėtume numatyti etiketes, o tada šias etiketes pateikti prižiūrimiems metodams. Šis metodas dažniausiai taikomas vaizdų duomenų rinkiniams, kur paprastai visi vaizdai nėra pažymėti.
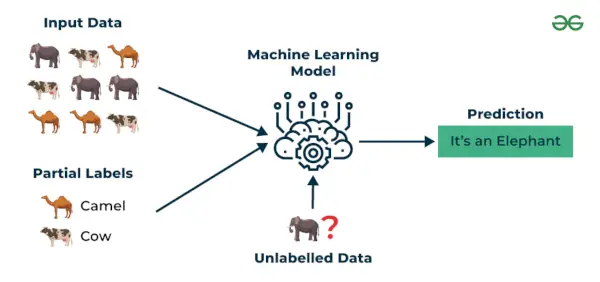
Pusiau prižiūrimas mokymasis
Supraskime tai pavyzdžio pagalba.
Pavyzdys : Apsvarstykite, kad kuriame kalbos vertimo modelį, o kiekvienos sakinių poros vertimų žymėjimas gali pareikalauti daug išteklių. Tai leidžia modeliams mokytis iš pažymėtų ir nepažymėtų sakinių porų, todėl jie tampa tikslesni. Dėl šios technikos gerokai pagerėjo mašininio vertimo paslaugų kokybė.
Pusiau prižiūrimų mokymosi metodų tipai
Yra keletas skirtingų pusiau prižiūrimų mokymosi metodų, kurių kiekvienas turi savo ypatybes. Kai kurie iš labiausiai paplitusių yra:
- Mokymasis grafikais, pusiau prižiūrimas: Šis metodas naudoja diagramą, kad pavaizduotų ryšius tarp duomenų taškų. Tada grafikas naudojamas etiketėms perkelti iš pažymėtų duomenų taškų į nepažymėtus duomenų taškus.
- Etiketės platinimas: Šis metodas pakartotinai perduoda etiketes iš pažymėtų duomenų taškų į nepažymėtus duomenų taškus, remiantis duomenų taškų panašumais.
- Bendras mokymas: Šis metodas apmoko du skirtingus mašininio mokymosi modelius skirtinguose nepažymėtų duomenų pogrupiuose. Tada abu modeliai naudojami vienas kito prognozėms pažymėti.
- Savarankiškas mokymas: Šis metodas parengia mašininio mokymosi modelį pagal pažymėtus duomenis, o tada naudoja modelį, kad numatytų nepažymėtų duomenų etiketes. Tada modelis perkvalifikuojamas pagal pažymėtus duomenis ir numatomas nepažymėtų duomenų etiketes.
- Generatyvieji priešingi tinklai (GAN) : GAN yra gilaus mokymosi algoritmo tipas, kurį galima naudoti sintetiniams duomenims generuoti. GAN gali būti naudojamas generuoti nepažymėtus duomenis, skirtus pusiau prižiūrimam mokymuisi, mokant du neuroninius tinklus – generatorių ir diskriminatorių.
Pusiau prižiūrimo mašininio mokymosi privalumai
- Tai leidžia geriau apibendrinti, palyginti su prižiūrimas mokymasis, nes reikia ir pažymėtų, ir nepažymėtų duomenų.
- Galima pritaikyti įvairiems duomenims.
Pusiau prižiūrimo mašininio mokymosi trūkumai
- Pusiau prižiūrimas metodai gali būti sudėtingesni, palyginti su kitais metodais.
- Tam vis tiek reikia šiek tiek pažymėti duomenys kurios gali būti ne visada prieinamos arba lengvai gaunamos.
- Nepažymėti duomenys gali atitinkamai paveikti modelio veikimą.
Pusiau prižiūrimo mokymosi taikymai
Štai keletas bendrų pusiau prižiūrimo mokymosi programų:
- Vaizdų klasifikavimas ir objektų atpažinimas : pagerinkite modelių tikslumą derindami nedidelį pažymėtų vaizdų rinkinį su didesniu nepažymėtų vaizdų rinkiniu.
- Natūralios kalbos apdorojimas (NLP) : pagerinkite kalbų modelių ir klasifikatorių našumą derindami nedidelį pažymėto teksto duomenų rinkinį su dideliu nepažymėto teksto kiekiu.
- Kalbos atpažinimas: Pagerinkite kalbos atpažinimo tikslumą, naudodami ribotą transkribuotų kalbos duomenų kiekį ir platesnį nepažymėto garso rinkinį.
- Rekomendavimo sistemos : pagerinkite suasmenintų rekomendacijų tikslumą, retą naudotojo elementų sąveikų rinkinį (pažymėtus duomenis) papildydami daugybe nepažymėtų naudotojo elgesio duomenų.
- Sveikatos priežiūra ir medicininis vaizdavimas : patobulinkite medicininių vaizdų analizę naudodami nedidelį pažymėtų medicininių vaizdų rinkinį kartu su didesniu nepažymėtų vaizdų rinkiniu.
4. Sustiprinimo mašininis mokymasis
Stiprinimo mašininis mokymasis algoritmas yra mokymosi metodas, kuris sąveikauja su aplinka, atlikdamas veiksmus ir atrasdamas klaidas. Bandymas, klaida ir delsimas yra svarbiausios stiprinimo mokymosi savybės. Taikant šią techniką, modelis ir toliau didina savo našumą, naudodamas atsiliepimus apie atlygį, kad išmoktų elgesį ar modelį. Šie algoritmai yra būdingi konkrečiai problemai, pvz. „Google Self Driving car“, AlphaGo, kur robotas konkuruoja su žmonėmis ir net savimi, kad „Go Game“ veiktų vis geriau. Kiekvieną kartą, kai pateikiame duomenis, jie išmoksta ir prideda duomenis prie savo žinių, kurios yra mokymo duomenys. Taigi, kuo daugiau jis mokosi, tuo geriau jis įgyja mokymąsi, taigi ir patirties.
Štai keletas dažniausiai naudojamų sustiprinimo mokymosi algoritmų:
- Q mokymasis: Q-learning yra RL algoritmas be modelio, kuris išmoksta Q funkciją, kuri susieja būsenas su veiksmais. Q funkcija įvertina laukiamą atlygį už tam tikrą veiksmą tam tikroje būsenoje.
- SARSA (state-Action-Reward-State-Action): SARSA yra kitas be modelio RL algoritmas, kuris išmoksta Q funkciją. Tačiau skirtingai nei Q-learning, SARSA atnaujina Q funkciją pagal faktiškai atliktą veiksmą, o ne optimalų veiksmą.
- Gilus Q mokymasis : Gilus Q mokymasis yra Q mokymosi ir gilaus mokymosi derinys. Gilus Q mokymasis naudoja neuroninį tinklą Q funkcijai reprezentuoti, o tai leidžia išmokti sudėtingus ryšius tarp būsenų ir veiksmų.
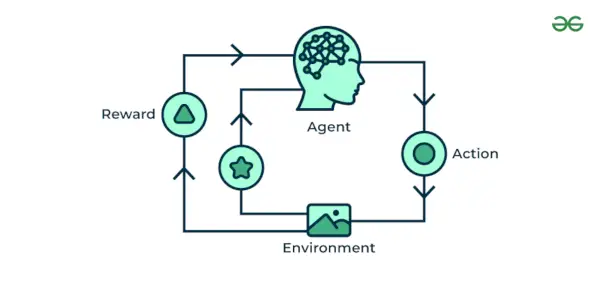
Sustiprinimo mašininis mokymasis
Supraskime tai remdamiesi pavyzdžiais.
Pavyzdys: Apsvarstykite, kad treniruojate AI agentas žaisti tokį žaidimą kaip šachmatai. Agentas tiria įvairius judesius ir, atsižvelgdamas į rezultatą, gauna teigiamą arba neigiamą grįžtamąjį ryšį. Stiprinamasis mokymasis taip pat randa programų, kuriose jie mokosi atlikti užduotis bendraudami su aplinka.
Stiprinimo mašininio mokymosi tipai
Yra du pagrindiniai stiprinimo mokymosi tipai:
Teigiamas stiprinimas
- Apdovanoja agentą už norimo veiksmo atlikimą.
- Skatina agentą pakartoti elgesį.
- Pavyzdžiai: skanėsto davimas šuniui už sėdėjimą, žaidimo taško skyrimas už teisingą atsakymą.
Neigiamas pastiprinimas
- Pašalina nepageidaujamą stimulą, skatinantį norimą elgesį.
- Atgraso agentą nuo tokio elgesio kartojimo.
- Pavyzdžiai: Garsaus garso signalo išjungimas, kai paspaudžiama svirtis, išvengiama bausmės atlikus užduotį.
Armatūros mašininio mokymosi privalumai
- Jis turi savarankišką sprendimų priėmimą, kuris puikiai tinka užduotims ir gali išmokti priimti sprendimų seką, pvz., robotiką ir žaidimą.
- Ši technika yra pageidaujama norint pasiekti ilgalaikių rezultatų, kuriuos pasiekti labai sunku.
- Jis naudojamas sprendžiant sudėtingas problemas, kurių negalima išspręsti įprastiniais metodais.
Stiprinimo mašininio mokymosi trūkumai
- Mokymo sustiprinimas Mokymosi agentai gali būti brangūs ir atimti daug laiko.
- Stiprinti mokymąsi nėra geriau nei paprastų problemų sprendimas.
- Tam reikia daug duomenų ir daug skaičiavimų, todėl tai nepraktiška ir brangu.
Sustiprinimo mašininio mokymosi taikymai
Štai keletas pastiprinimo mokymosi programų:
- Žaidimas Žaidimas : RL gali išmokyti agentus žaisti žaidimus, net sudėtingus.
- Robotika : RL gali išmokyti robotus atlikti užduotis savarankiškai.
- Autonominės transporto priemonės : RL gali padėti savarankiškai vairuojantiems automobiliams orientuotis ir priimti sprendimus.
- Rekomendavimo sistemos : RL gali patobulinti rekomendacijų algoritmus mokydamasi naudotojo nuostatų.
- Sveikatos apsauga : RL gali būti naudojamas optimizuoti gydymo planus ir vaistų atradimą.
- Natūralios kalbos apdorojimas (NLP) : RL gali būti naudojamas dialogų sistemose ir pokalbių robotuose.
- Finansai ir prekyba : RL gali būti naudojamas algoritminei prekybai.
- Tiekimo grandinės ir atsargų valdymas : RL gali būti naudojamas tiekimo grandinės operacijoms optimizuoti.
- Energijos valdymas : RL gali būti naudojamas energijos suvartojimui optimizuoti.
- AI žaidimai : RL gali būti naudojamas kuriant intelektualesnius ir labiau prisitaikančius NPC vaizdo žaidimuose.
- Prisitaikantys asmeniniai asistentai : RL gali būti naudojamas asmeniniams asistentams tobulinti.
- Virtuali realybė (VR) ir papildyta realybė (AR): RL gali būti naudojamas kuriant įtraukias ir interaktyvias patirtis.
- Pramonės kontrolė : RL gali būti naudojamas pramoniniams procesams optimizuoti.
- Išsilavinimas : RL gali būti naudojamas kuriant adaptyvias mokymosi sistemas.
- Žemdirbystė : RL gali būti naudojamas žemės ūkio operacijoms optimizuoti.
Turite patikrinti, mūsų išsamus straipsnis : Mašininio mokymosi algoritmai
matricos programa c kalba
Išvada
Apibendrinant galima pasakyti, kad kiekvienas mašininio mokymosi tipas atlieka savo tikslą ir prisideda prie bendro vaidmens kuriant patobulintas duomenų numatymo galimybes, be to, jis gali pakeisti įvairias pramonės šakas, pvz. Duomenų mokslas . Tai padeda susidoroti su didžiuliu duomenų kūrimu ir duomenų rinkinių valdymu.
Mašininio mokymosi tipai – DUK
1. Su kokiais iššūkiais susiduriama mokantis prižiūrint?
Kai kurie iššūkiai, su kuriais susiduriama mokantis prižiūrint, daugiausia apima klasių disbalanso šalinimą, aukštos kokybės paženklintus duomenis ir perdėto pritaikymo išvengimą, kai modeliai blogai veikia realiojo laiko duomenis.
2. Kur galime pritaikyti prižiūrimą mokymąsi?
Prižiūrimas mokymasis dažniausiai naudojamas atliekant tokias užduotis kaip el. pašto šiukšlių analizavimas, vaizdų atpažinimas ir nuotaikų analizė.
3. Kaip atrodo mašininio mokymosi ateitis?
Mašininis mokymasis kaip ateities perspektyva gali veikti tokiose srityse kaip orų ar klimato analizė, sveikatos priežiūros sistemos ir autonominis modeliavimas.
4. Kokie yra skirtingi mašininio mokymosi tipai?
Yra trys pagrindiniai mašininio mokymosi tipai:
- Prižiūrimas mokymasis
- Mokymasis be priežiūros
- Sustiprinimo mokymasis
5. Kokie yra dažniausiai pasitaikantys mašininio mokymosi algoritmai?
Kai kurie iš labiausiai paplitusių mašininio mokymosi algoritmų yra šie:
- Tiesinė regresija
- Logistinė regresija
- Palaikykite vektorines mašinas (SVM)
- K-artimiausi kaimynai (KNN)
- Sprendimų medžiai
- Atsitiktiniai miškai
- Dirbtiniai neuroniniai tinklai