- dnorm()
dnorm(x, mean, sd)>pnorm()
pnorm(x, mean, sd)>qnorm()
qnorm(p, mean, sd)>rnorm()
rnorm(n, mean, sd)>kur,
– x reiškia reikšmių duomenų rinkinį – vidurkis (x) reiškia duomenų rinkinio vidurkį x . Numatytoji reikšmė yra 0.>– sd(x) reiškia standartinį duomenų rinkinio nuokrypį x . Numatytoji vertė yra 1.>– n yra stebėjimų skaičius. – p yra tikimybių vektorius
Funkcijos, skirtos normaliam pasiskirstymui generuoti R
dnorm()
dnorm()> funkcija R programavime matuoja pasiskirstymo tankio funkciją. Statistikoje jis matuojamas pagal žemiau esančią formulę:>kur,
 yra menkas ir
yra menkas ir 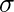 yra standartinis nuokrypis. Sintaksė:
yra standartinis nuokrypis. Sintaksė: dnorm(x, mean, sd)>Pavyzdys:
# creating a sequence of values> # between -15 to 15 with a difference of 0.1> x>=> seq(>->15>,>15>, by>=>0.1>)> > y>=> dnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file>=>'dnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Išvestis:
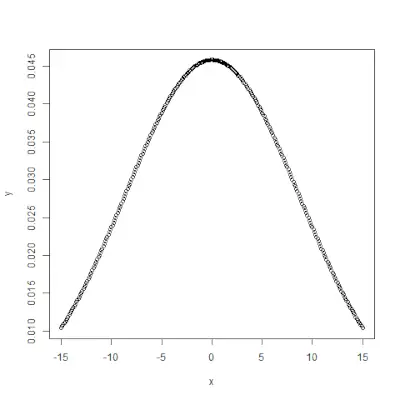
pnorm()
pnorm()> funkcija yra kaupiamoji pasiskirstymo funkcija, kuri matuoja tikimybę, kad atsitiktinis skaičius X įgis reikšmę, mažesnę arba lygią x, t. y. statistikoje jis pateikiamas>Sintaksė:
pnorm(x, mean, sd)>Pavyzdys:
# creating a sequence of values> # between -10 to 10 with a difference of 0.1> x <>-> seq(>->10>,>10>, by>=>0.1>)> > y <>-> pnorm(x, mean>=> 2.5>, sd>=> 2>)> > # output to be present as PNG file> png(>file>=>'pnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Išvestis:
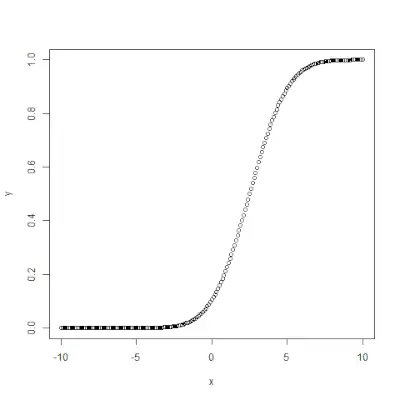
qnorm()
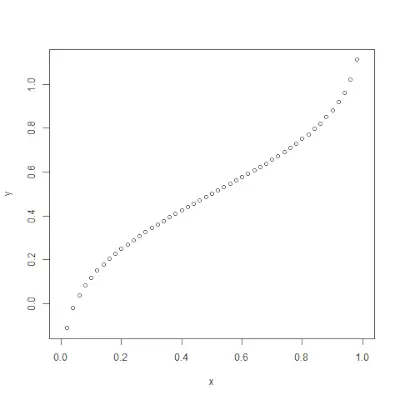
qnorm()> funkcija yra atvirkštinė pnorm()>funkcija. Jis paima tikimybės vertę ir pateikia išvestį, atitinkančią tikimybės vertę. Tai naudinga ieškant normalaus skirstinio procentilių. Sintaksė: qnorm(p, mean, sd)>Pavyzdys:
# Create a sequence of probability values> # incrementing by 0.02.> x <>-> seq(>0>,>1>, by>=> 0.02>)> > y <>-> qnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file> => 'qnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # Save the file.> dev.off()> |
>
>Išvestis:
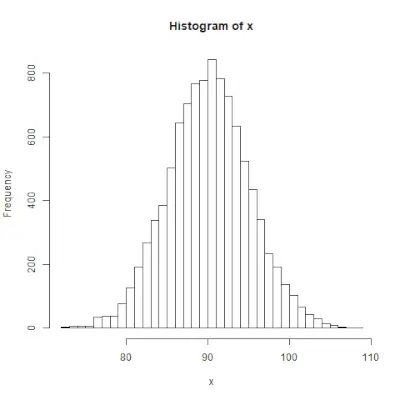
rnorm()
rnorm()> R programavimo funkcija naudojama atsitiktinių skaičių, kurie paprastai paskirstomi, vektoriui generuoti. Sintaksė: rnorm(x, mean, sd)>Pavyzdys:
# Create a vector of 1000 random numbers> # with mean=90 and sd=5> x <>-> rnorm(>10000>, mean>=>90>, sd>=>5>)> > # output to be present as PNG file> png(>file> => 'rnormExample.webp'>)> > # Create the histogram with 50 bars> hist(x, breaks>=>50>)> > # Save the file.> dev.off()> |
>
>Išvestis: