„Excel“ lapai yra labai instinktyvūs ir patogūs vartotojui, todėl jie puikiai tinka manipuliuoti dideliais duomenų rinkiniais net ir ne tokiems techniniams žmonėms. Jei ieškote vietų, kur išmokti valdyti ir automatizuoti „Excel“ failų turinį Python , neziurek i prieki. Jūs esate tinkamoje vietoje.
Šiame straipsnyje sužinosite, kaip naudoti Pandos dirbti su Excel skaičiuoklėmis. Šiame straipsnyje mes sužinosime apie:
- Skaityti Excel failas naudojant Pandas Python
- Pandų diegimas ir importavimas
- Kelių Excel lapų skaitymas naudojant Pandas
- Įvairių Pandos funkcijų taikymas
„Excel“ failo skaitymas naudojant „Pandas“ programoje Python
Pandų montavimas
Norėdami įdiegti Pandas Python, komandų eilutėje galime naudoti šią komandą:
pip install pandas>
Norėdami įdiegti Pandas Anaconda, galime naudoti šią komandą Anaconda terminale:
conda install pandas>
Importuojame pandas
Visų pirma, turime importuoti Pandas modulį, kurį galima padaryti paleidus komandą:
Python3
import> pandas as pd> |
>
>
Įvesties failas: Tarkime, kad „Excel“ failas atrodo taip
1 lapas:

1 lapas
2 lapas:
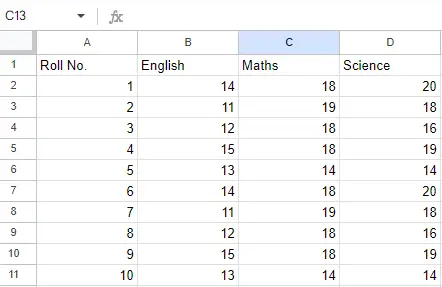
2 lapas
Dabar galime importuoti „Excel“ failą naudodami „Read_excel“ funkciją „Pandas“, kad skaitytume „Excel“ failą naudodami „Pandas“ programoje Python. Antrasis teiginys nuskaito duomenis iš „Excel“ ir išsaugo juos pandos duomenų rėmelyje, kurį vaizduoja kintamasis newData.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Išvestis:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Kelių lapų įkėlimas naudojant Concat() metodą
Jei „Excel“ darbaknygėje yra keli lapai, komanda importuos duomenis iš pirmojo lapo. Norėdami sukurti duomenų rėmelį su visais darbaknygės lapais, paprasčiausias būdas yra sukurti skirtingus duomenų rėmelius atskirai ir juos sujungti. „Read_excel“ metodas naudoja argumentus lapo_pavadinimas ir indekso_kolas, kur galime nurodyti lapą, iš kurio turi būti sudarytas rėmelis, o „index_col“ nurodo pavadinimo stulpelį, kaip parodyta toliau:
Pavyzdys:
Trečiasis teiginys sujungia abu lapus. Dabar norėdami patikrinti visą duomenų rėmelį, galime tiesiog paleisti šią komandą:
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Išvestis:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Head() ir Tail() metodai pandose
Norėdami peržiūrėti 5 stulpelius iš duomenų rėmelio viršaus ir apačios, galime paleisti komandą. Tai galva() ir uodega () metodas taip pat ima argumentus kaip skaičius, kad būtų rodomas rodomų stulpelių skaičius.
Python3
masyvas java
print>(newData.head())> print>(newData.tail())> |
>
>
Išvestis:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Shape() metodas
The forma() metodas galima naudoti norint peržiūrėti eilučių ir stulpelių skaičių duomenų rėmelyje taip:
Python3
newData.shape> |
>
>
Išvestis:
(20, 3)>
Sort_values() metodas Pandas
Jei kuriame nors stulpelyje yra skaitmeninių duomenų, galime rūšiuoti tą stulpelį naudodami Rūšiuoti_vertes() metodas pandose yra toks:
Python3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Tarkime, kad norime 5 geriausių rūšiuoto stulpelio reikšmių, čia galime naudoti head () metodą:
Python3
sorted_column.head(>5>)> |
>
>
Išvestis:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Tai galime padaryti naudodami bet kurį skaitinį duomenų rėmelio stulpelį, kaip parodyta toliau:
Python3
newData[>'Maths'>].head()> |
>
>
Išvestis:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Pandos Apibūdinkite() metodą
Tarkime, kad mūsų duomenys dažniausiai yra skaitiniai. Naudodami duomenų rėmelį galime gauti statistinę informaciją, pvz., vidurkį, maks., min. ir kt apibūdinti() metodas, kaip parodyta žemiau:
Python3
newData.describe()> |
>
>
Išvestis:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Tai taip pat galima padaryti atskirai visiems skaitiniams stulpeliams naudojant šią komandą:
Python3
newData[>'English'>].mean()> |
>
>
Išvestis:
14.3>
Kitą statistinę informaciją taip pat galima apskaičiuoti taikant atitinkamus metodus. Kaip ir „Excel“, taip pat galima taikyti formules, o apskaičiuotus stulpelius sukurti taip:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
Išvestis:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Panaudoję duomenis duomenų rėmelyje, galime eksportuoti duomenis atgal į Excel failą naudodami metodą to_excel. Norėdami tai padaryti, turime nurodyti išvesties „Excel“ failą, kuriame turi būti įrašyti transformuoti duomenys, kaip parodyta toliau:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Išvestis:
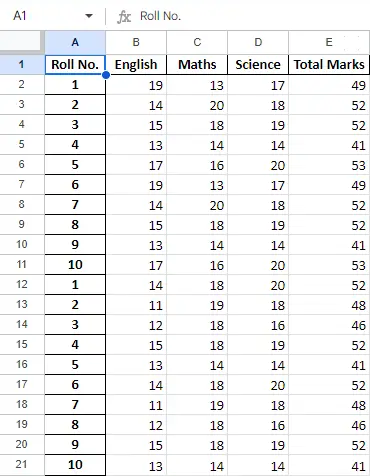
Galutinis lapas