Prižiūrimas ir neprižiūrimas mokymasis yra du mašininio mokymosi būdai. Tačiau abu metodai naudojami skirtinguose scenarijuose ir su skirtingais duomenų rinkiniais. Žemiau pateikiamas abiejų mokymosi metodų paaiškinimas ir jų skirtumų lentelė.
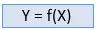
Prižiūrimas mašininis mokymasis:
Prižiūrimas mokymasis yra mašininio mokymosi metodas, kai modeliai mokomi naudojant pažymėtus duomenis. Prižiūrimo mokymosi metu modeliai turi rasti susiejimo funkciją, kad susietų įvesties kintamąjį (X) su išvesties kintamuoju (Y).
Prižiūrėtam mokymuisi reikalinga priežiūra, norint parengti modelį, o tai panašu į tai, kaip mokinys mokosi dalykų dalyvaujant mokytojui. Prižiūrimas mokymasis gali būti naudojamas dviejų tipų problemoms spręsti: klasifikacija ir Regresija .
Sužinokite daugiau Prižiūrimas mašininis mokymasis
Pavyzdys: Tarkime, kad turime įvairių rūšių vaisių vaizdą. Mūsų prižiūrimo mokymosi modelio užduotis yra nustatyti vaisius ir atitinkamai juos klasifikuoti. Taigi, norėdami atpažinti vaizdą prižiūrimo mokymosi metu, pateiksime įvesties duomenis ir išvestį, o tai reiškia, kad modeliuosime pagal kiekvieno vaisiaus formą, dydį, spalvą ir skonį. Baigę mokymus išbandysime modelį padovanodami naują vaisių rinkinį. Modelis identifikuos vaisius ir nuspės produkciją naudodamas tinkamą algoritmą.
Neprižiūrimas mašininis mokymasis:
Neprižiūrimas mokymasis yra dar vienas mašininio mokymosi metodas, kai modeliai nustatomi iš nepažymėtų įvesties duomenų. Neprižiūrimo mokymosi tikslas – iš įvesties duomenų surasti struktūrą ir modelius. Mokymuisi be priežiūros nereikia jokios priežiūros. Vietoj to, ji pati suranda šablonus iš duomenų.
Sužinokite daugiau Neprižiūrimas mašininis mokymasis
Neprižiūrimas mokymasis gali būti naudojamas dviejų tipų problemoms spręsti: Klasterizavimas ir asociacija .
Pavyzdys: Norėdami suprasti neprižiūrimą mokymąsi, naudosime aukščiau pateiktą pavyzdį. Taigi, skirtingai nei prižiūrimas mokymasis, čia modeliui jokios priežiūros neteiksime. Mes tiesiog pateiksime modelio įvesties duomenų rinkinį ir leisime modeliui rasti šablonus iš duomenų. Tinkamo algoritmo pagalba modelis pats treniruosis ir suskirstys vaisius į skirtingas grupes pagal labiausiai panašius požymius.
Pagrindiniai skirtumai tarp prižiūrimo ir neprižiūrimo mokymosi pateikiami toliau:
| Prižiūrimas mokymasis | Mokymasis be priežiūros |
|---|---|
| Prižiūrimi mokymosi algoritmai mokomi naudojant pažymėtus duomenis. | Neprižiūrimi mokymosi algoritmai mokomi naudojant nepažymėtus duomenis. |
| Prižiūrimas mokymosi modelis naudoja tiesioginį grįžtamąjį ryšį, kad patikrintų, ar jis numato teisingą rezultatą, ar ne. | Neprižiūrimas mokymosi modelis nepriima jokio grįžtamojo ryšio. |
| Prižiūrimas mokymosi modelis numato rezultatą. | Neprižiūrimas mokymosi modelis suranda paslėptus duomenų šablonus. |
| Prižiūrimo mokymosi metu įvesties duomenys pateikiami modeliui kartu su išvestimi. | Neprižiūrimo mokymosi metu modeliui pateikiami tik įvesties duomenys. |
| Prižiūrimo mokymosi tikslas yra parengti modelį, kad jis galėtų numatyti išvestį, kai jam bus pateikti nauji duomenys. | Neprižiūrimo mokymosi tikslas yra rasti paslėptus modelius ir naudingas įžvalgas iš nežinomo duomenų rinkinio. |
| Prižiūrėtam mokymuisi reikalinga priežiūra, kad būtų galima išmokyti modelį. | Mokymuisi be priežiūros nereikia jokios priežiūros, kad būtų galima išmokyti modelį. |
| Prižiūrimas mokymasis gali būti suskirstytas į kategorijas klasifikacija ir Regresija problemų. | Mokymasis be priežiūros gali būti klasifikuojamas Klasterizavimas ir Asociacijos problemų. |
| Prižiūrimas mokymasis gali būti naudojamas tais atvejais, kai žinome įvestį ir atitinkamus rezultatus. | Neprižiūrimas mokymasis gali būti naudojamas tais atvejais, kai turime tik įvesties duomenis ir neturime atitinkamų išvesties duomenų. |
| Prižiūrimas mokymosi modelis duoda tikslų rezultatą. | Neprižiūrimas mokymosi modelis gali duoti mažiau tikslius rezultatus, palyginti su prižiūrimu mokymusi. |
| Prižiūrimas mokymasis nėra artimas tikram dirbtiniam intelektui, nes šiuo atveju pirmiausia mokome kiekvieno duomenų modelį, o tik tada jis gali numatyti teisingą išvestį. | Mokymasis be priežiūros yra artimesnis tikrajam dirbtiniam intelektui, nes jis mokosi panašiai, kaip vaikas išmoksta kasdienių dalykų iš savo patirties. |
| Tai apima įvairius algoritmus, tokius kaip tiesinė regresija, logistinė regresija, paramos vektorių mašina, kelių klasių klasifikacija, sprendimų medis, Bajeso logika ir kt. | Tai apima įvairius algoritmus, tokius kaip grupavimas, KNN ir Apriori algoritmas. |