Pandos dataframe.corr() naudojamas norint rasti porinę visų stulpelių koreliaciją Pandas duomenų rėmelyje Python. Bet koks NaN vertės automatiškai neįtraukiamos. Jei norite nepaisyti jokių neskaitinių reikšmių, naudokite parametrą numeric_only = True. Šiame straipsnyje mes sužinosime apie DataFrame.corr() metodą Python .
Pandas DataFrame corr() Metodo sintaksė
Sintaksė: DataFrame.corr(self, method='pearson', min_periods=1, numeric_only = False)
Parametrai:
- metodas:
- Pearsonas: standartinis koreliacijos koeficientas
- Kendall: Kendall Tau koreliacijos koeficientas
- spearman: Spearman rango koreliacija
- min_periods : Minimalus stebėjimų skaičius, reikalingas vienai stulpelių porai, kad rezultatas būtų tinkamas. Šiuo metu galima tik Pearsono ir Spearman koreliacijai
- numeric_only : ar turi būti naudojamos tik skaitinės reikšmės, ar ne. Pagal numatytuosius nustatymus jis nustatytas į False.
Grąžina: count :y : DataFrame
Pandos duomenų koreliacijos corr() metodas
Gera koreliacija priklauso nuo naudojimo, tačiau galima drąsiai teigti, kad turite bent 0,6 (arba -0,6), kad tai būtų galima vadinti gera koreliacija. Paprastas pavyzdys, rodantis, kaip veikia koreliacija Python .
Python3
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
>
Išvestis
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Pavyzdinio duomenų rėmelio kūrimas
Pirmųjų 10 duomenų rėmelio eilučių spausdinimas.
Pastaba: Kintamojo koreliacija su pačiu savimi yra 1. Norėdami gauti nuorodą į CSV failą, naudojamą kode, spustelėkite čia
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
Išvestis

Python Pandas DataFrame corr() metodo pavyzdžiai
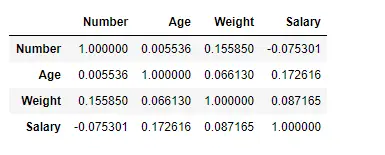
Raskite koreliaciją tarp stulpelių naudodami Pearsono metodą
Čia mes naudojame funkciją corr () norėdami rasti koreliaciją tarp duomenų rėmo stulpelių naudodami „Pearson“ metodą. Duomenų rėmelyje turime tik keturis skaitinius stulpelius. Išvesties duomenų rėmelis gali būti interpretuojamas kaip bet kuriame langelyje, eilutės kintamojo koreliacija su stulpelio kintamuoju yra langelio reikšmė. Kaip minėta anksčiau, kintamojo koreliacija su savimi yra 1. Dėl šios priežasties visos įstrižainės reikšmės yra 1,00.
Python3
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
Išvestis
k artimiausias kaimynas
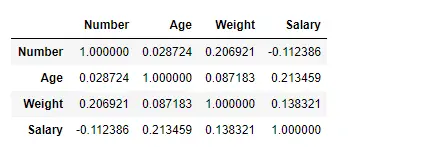
Raskite koreliaciją tarp stulpelių naudodami Kendall metodą
Naudokite funkciją Pandas df.corr(), kad rastumėte koreliaciją tarp duomenų rėmelio stulpelių, naudodami „kendall“ metodą. Išvesties duomenų rėmelis gali būti interpretuojamas kaip bet kuriame langelyje, eilutės kintamojo koreliacija su stulpelio kintamuoju yra langelio reikšmė. Kaip minėta anksčiau, kintamojo koreliacija su savimi yra 1. Dėl šios priežasties visos įstrižainės reikšmės yra 1,00.
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
>
>
Išvestis