BERT, akronimas Transformatorių dvikrypčių kodavimo įrenginių atvaizdams , yra atvirojo kodo mašininio mokymosi sistema sukurta sferai natūralios kalbos apdorojimas (NLP) . Šią sistemą, atsiradusią 2018 m., sukūrė „Google AI Language“ mokslininkai. Straipsnio tikslas yra ištirti ETRI architektūra, veikimas ir programos .
Kas yra BERT?
BERT (transformatorių dvikrypčiai kodavimo įrenginiai) naudoja transformatorių pagrįstą neuroninį tinklą, kad suprastų ir generuotų į žmogų panašią kalbą. BERT naudoja tik koduotuvo architektūrą. Originale Transformatoriaus architektūra , yra ir kodavimo, ir dekodavimo moduliai. Sprendimas BERT naudoti tik kodavimo architektūrą rodo, kad pagrindinis dėmesys turėtų būti skiriamas įvesties sekų supratimui, o ne išvesties sekų generavimui.
Dvikryptis ETRI požiūris
Tradiciniai kalbos modeliai apdoroja tekstą nuosekliai – iš kairės į dešinę arba iš dešinės į kairę. Šis metodas apriboja modelio suvokimą iki tiesioginio konteksto, esančio prieš tikslinį žodį. BERT taiko dvikryptį metodą, atsižvelgdama į kairįjį ir dešinįjį sakinio žodžių kontekstą, užuot analizavusi tekstą paeiliui, BERT žiūri į visus sakinio žodžius vienu metu.
Pavyzdys: krantas yra upės _______.
Taikant vienakryptį modelį, tuščiosios dalies supratimas labai priklausytų nuo ankstesnių žodžių, o modeliui gali būti sunku atskirti, ar bankas reiškia finansų įstaigą, ar upės krantą.
BERT, būdamas dvikryptis, vienu metu atsižvelgia į kairįjį (krantas yra ant upės), ir į dešinįjį (upės) kontekstą, suteikdamas galimybę geriau suprasti. Ji supranta, kad trūkstamas žodis greičiausiai yra susijęs su banko geografine padėtimi, o tai parodo kontekstinį turtingumą, kurį suteikia dvikryptis požiūris.
Išankstinis mokymas ir koregavimas
BERT modelis vyksta dviem etapais:
- Išankstinis mokymas apie didelį nepažymėto teksto kiekį, norint išmokti kontekstinio įterpimo.
- Tikslus pažymėtų duomenų derinimas konkrečiams NLP užduotys.
Išankstinis mokymas apie didelius duomenis
- BERT yra iš anksto apmokytas naudoti daug nepažymėtų tekstinių duomenų. Modelis mokosi kontekstinio įterpimo, tai yra žodžių, atsižvelgiančių į juos supantį kontekstą sakinyje, atvaizdavimas.
- BERT atlieka įvairias nekontroliuojamas išankstinio mokymo užduotis. Pavyzdžiui, jis gali išmokti nuspėti trūkstamus žodžius sakinyje (užmaskuotos kalbos modelis arba MLM užduotis), suprasti ryšį tarp dviejų sakinių arba numatyti kitą poros sakinį.
Tikslus pažymėtų duomenų derinimas
- Po parengiamojo mokymo etapo BERT modelis, aprūpintas kontekstiniais įterpimais, tiksliai sureguliuojamas konkrečioms natūralios kalbos apdorojimo (NLP) užduotims atlikti. Šis žingsnis pritaiko modelį tikslingesnėms programoms, pritaikant jo bendrą kalbos supratimą prie konkrečios užduoties niuansų.
- BERT yra tiksliai sureguliuotas naudojant pažymėtus duomenis, susijusius su dominančiomis užduotimis. Šios užduotys gali apimti jausmų analizę, atsakymus į klausimus, pavadinto subjekto atpažinimas , arba bet kuri kita NLP programa. Modelio parametrai koreguojami, kad būtų optimizuotas jo veikimas pagal konkrečius atliekamos užduoties reikalavimus.
Vieninga BERT architektūra leidžia jai prisitaikyti prie įvairių tolesnių užduočių su minimaliais pakeitimais, todėl ji yra universali ir labai efektyvi priemonė natūralios kalbos supratimas ir apdorojimas.
Kaip veikia BERT?
BERT sukurtas kalbos modeliui generuoti, todėl naudojamas tik kodavimo mechanizmas. Žetonų seka įvedama į transformatoriaus kodavimo įrenginį. Šie žetonai pirmiausia įterpiami į vektorius ir apdorojami neuroniniame tinkle. Išvestis yra vektorių seka, kurių kiekvienas atitinka įvesties žetoną, pateikiant kontekstualizuotus vaizdus.
Mokant kalbos modelius, numatymo tikslo nustatymas yra iššūkis. Daugelis modelių numato kitą sekos žodį, o tai yra kryptingas požiūris ir gali apriboti mokymąsi kontekste. BERT sprendžia šį iššūkį dviem naujoviškomis mokymo strategijomis:
- Užmaskuotos kalbos modelis (MLM)
- Kito sakinio numatymas (NSP)
1. Užmaskuotos kalbos modelis (MLM)
Išankstinio BERT mokymo procese dalis žodžių kiekvienoje įvesties sekoje yra užmaskuojama, o modelis mokomas numatyti pirmines šių užmaskuotų žodžių reikšmes, remiantis aplinkinių žodžių teikiamu kontekstu.
Paprastais žodžiais tariant,
- Maskuojantys žodžiai: Prieš mokydamasi iš sakinių, BERT paslepia kai kuriuos žodžius (apie 15 %) ir pakeičia juos specialiu simboliu, pvz., [KAUKĖ].
- Atspėti paslėptus žodžius: BERT darbas yra išsiaiškinti, kas yra šie paslėpti žodžiai, žiūrint į juos supančius žodžius. Tai tarsi žaidimas atspėti, kur trūksta kai kurių žodžių, ir BERT bando užpildyti tuščias vietas.
- Kaip BERT mokosi:
- BERT prideda specialų sluoksnį savo mokymosi sistemos viršuje, kad galėtų spėti. Tada ji patikrina, kiek jos spėjimai yra arti tikrųjų paslėptų žodžių.
- Jis tai daro paversdamas savo spėjimus į tikimybes, sakydamas: „Manau, kad šis žodis yra X, ir aš esu tuo tikras.
- Ypatingas dėmesys paslėptiems žodžiams
- Pagrindinis BERT dėmesys mokymų metu yra skirtas šių paslėptų žodžių teisingumui. Jam mažiau rūpi nuspėti nepaslėptus žodžius.
- Taip yra todėl, kad tikras iššūkis yra išsiaiškinti trūkstamas dalis, o ši strategija padeda BERT tikrai gerai suprasti žodžių prasmę ir kontekstą.
Kalbant technine prasme,
- BERT prideda klasifikavimo sluoksnį ant kodavimo įrenginio išvesties. Šis sluoksnis yra labai svarbus numatant užmaskuotus žodžius.
- Klasifikavimo sluoksnio išvesties vektoriai padauginami iš įterpimo matricos, transformuojant juos į žodyno dimensiją. Šis veiksmas padeda suderinti numatomus vaizdus su žodyno erdve.
- Kiekvieno žodžio tikimybė žodyne apskaičiuojama naudojant SoftMax aktyvinimo funkcija . Šis veiksmas sukuria kiekvienos užmaskuotos pozicijos tikimybių pasiskirstymą visame žodyne.
- Treniruotės metu naudojama praradimo funkcija atsižvelgia tik į užmaskuotų verčių numatymą. Modelis yra baudžiamas už nukrypimą tarp jo prognozių ir faktinių užmaskuotų žodžių reikšmių.
- Modelis konverguoja lėčiau nei kryptiniai modeliai. Taip yra todėl, kad treniruočių metu BERT rūpinasi tik užmaskuotų verčių numatymu, nepaisydama neužmaskuotų žodžių numatymo. Taikant šią strategiją pasiektas didesnis konteksto suvokimas kompensuoja lėtesnę konvergenciją.
2. Kito sakinio numatymas (NSP)
BERT numato, ar antrasis sakinys yra susijęs su pirmuoju. Tai atliekama transformuojant [CLS] žetono išvestį į 2 × 1 formos vektorių, naudojant klasifikavimo sluoksnį, o tada naudojant SoftMax apskaičiuojant tikimybę, ar antrasis sakinys seka pirmąjį.
- Mokymo procese BERT išmoksta suprasti sakinių porų santykį, numatant, ar antrasis sakinys yra po pirmojo pradiniame dokumente.
- 50 % įvesties porų antrasis sakinys yra paskesnis sakinys pradiniame dokumente, o kiti 50 % turi atsitiktinai pasirinktą sakinį.
- Padėti modeliui atskirti sujungtas ir atjungtas sakinių poras. Įvestis apdorojama prieš įvedant modelį:
- Pirmojo sakinio pradžioje įterpiamas [CLS] ženklas, o kiekvieno sakinio pabaigoje – [SEP] ženklas.
- Prie kiekvieno žetono pridedamas sakinys, nurodantis A arba B sakinį.
- Padėties įterpimas nurodo kiekvieno žetono padėtį sekoje.
- BERT numato, ar antrasis sakinys yra susijęs su pirmuoju. Tai atliekama transformuojant [CLS] žetono išvestį į 2 × 1 formos vektorių, naudojant klasifikavimo sluoksnį, o tada naudojant SoftMax apskaičiuojant tikimybę, ar antrasis sakinys seka pirmąjį.
BERT modelio treniruočių metu kartu treniruojamas Masked LM ir Next Sentence Prediction. Modeliu siekiama sumažinti bendrą maskuoto LM ir kito sakinio numatymo praradimo funkciją, todėl sukuriamas tvirtas kalbos modelis, turintis geresnes galimybes suprasti sakinių kontekstą ir ryšius tarp sakinių.
Kodėl treniruoti Masked LM ir kito sakinio numatymą kartu?
Masked LM padeda BERT suprasti sakinio kontekstą ir Kito sakinio numatymas padeda BERT suvokti ryšį arba santykį tarp sakinių porų. Taigi abiejų strategijų mokymas kartu užtikrina, kad BERT išmoks platų ir visapusišką kalbos supratimą, fiksuodama tiek sakinių detales, tiek srautą tarp sakinių.
BERT architektūros
BERT architektūra yra daugiasluoksnis dvikryptis transformatoriaus kodavimo įrenginys, kuris yra gana panašus į transformatoriaus modelį. Transformatoriaus architektūra yra kodavimo-dekoderio tinklas, kuris naudoja dėmesys į save kodavimo pusėje ir dėmesys dekoderio pusėje.
- BERTBAZĖturi 1 2 sluoksniai Encoder krūvoje o BERTDIDELISturi 24 sluoksniai Encoder krūvoje . Tai daugiau nei Transformatoriaus architektūra, aprašyta pradiniame dokumente ( 6 kodavimo sluoksniai ).
- BERT architektūros (BASE ir LARGE) taip pat turi didesnius perdavimo tinklus (atitinkamai 768 ir 1024 paslėptus blokus) ir daugiau dėmesio galvos (atitinkamai 12 ir 16) nei Transformatoriaus architektūra, pasiūlyta pirminiame dokumente. Jame yra 512 paslėptų vienetų ir 8 dėmesio galvutės .
- BERTBAZĖyra 110M parametrų, o BERTDIDELISturi 340M parametrus.

BERT BASE ir BERT LARGE architektūra.
Šis modelis paima CLS žetoną pirmiausia kaip įvestį, po to seka žodžių seka kaip įvestis. Čia CLS yra klasifikavimo ženklas. Tada jis perduoda įvestį į aukščiau nurodytus sluoksnius. Kiekvienas sluoksnis taikomas dėmesys į save ir perduoda rezultatą per persiuntimo tinklą, po to jis perduodamas kitam koduotuvui. Modelis išveda paslėpto dydžio vektorių ( 768 BERT BASE). Jei norime išvesti šio modelio klasifikatorių, galime paimti išvestį, atitinkančią CLS prieigos raktą.
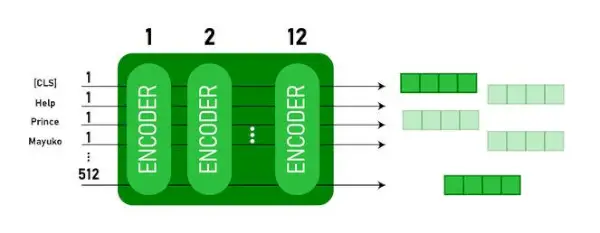
BERT išvestis kaip įterpimai
Dabar šis išmokytas vektorius gali būti naudojamas atliekant daugybę užduočių, tokių kaip klasifikavimas, vertimas ir kt. Pavyzdžiui, popierius pasiekia puikių rezultatų tik naudojant vieną sluoksnį Neuroninis tinklas pagal BERT modelį klasifikavimo užduotyje.
Kaip naudoti BERT modelį NLP?
BERT gali būti naudojamas įvairioms natūralios kalbos apdorojimo (NLP) užduotims, tokioms kaip:
1. Klasifikavimo užduotis
- BERT gali būti naudojamas tokioms klasifikavimo užduotims atlikti sentimentų analizė , tikslas yra suskirstyti tekstą į skirtingas kategorijas (teigiamas / neigiamas / neutralus), BERT gali būti naudojamas pridedant klasifikavimo sluoksnį transformatoriaus išvesties viršuje [CLS] prieigos raktui.
- Žetonas [CLS] reiškia sukauptą informaciją iš visos įvesties sekos. Tada šis bendras vaizdas gali būti naudojamas kaip klasifikavimo sluoksnio įvestis, kad būtų galima numatyti konkrečią užduotį.
2. Atsakymas į klausimą
- Atsakymų į klausimus užduotis, kai modelis reikalingas atsakymui rasti ir pažymėti tam tikroje teksto sekoje, BERT gali būti apmokytas šiuo tikslu.
- BERT mokomas atsakyti į klausimus, išmokdamas du papildomus vektorius, žyminčius atsakymo pradžią ir pabaigą. Mokymų metu modeliui pateikiami klausimai ir atitinkamos ištraukos, išmokstama numatyti atsakymo pradžios ir pabaigos pozicijas ištraukoje.
3. Pavadinto subjekto atpažinimas (NER)
- BERT gali būti naudojamas NER, kurio tikslas yra identifikuoti ir klasifikuoti subjektus (pvz., asmenį, organizaciją, datą) teksto seka.
- BERT pagrindu sukurtas NER modelis mokomas paimant kiekvieno transformatoriaus žetono išvesties vektorių ir įvedant jį į klasifikavimo sluoksnį. Sluoksnis numato įvardytą objekto etiketę kiekvienam prieigos raktui, nurodydamas objekto tipą, kurį jis atstovauja.
Kaip žymėti ir koduoti tekstą naudojant BERT?
Norėdami žymėti ir koduoti tekstą naudodami BERT, naudosime „Python“ transformatoriaus biblioteką.
Komanda įdiegti transformatorius:
!pip install transformers>
- Mes įkelsime iš anksto paruoštą BERT žetoną su didžiosiomis raidėmis žodynu, naudodami BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(tekstas) tokenizuoja įvesties tekstą ir paverčia jį žetonų ID seka.
- spausdinti (žetonų ID:, kodavimas) atspausdina po kodavimo gautus žetonų ID.
- tokenizer.convert_ids_to_tokens(encoding) konvertuoja žetonų ID atgal į atitinkamus žetonus.
- spausdinti (žetonai:, žetonai) atspausdina žetonus, gautus konvertavus žetonų ID
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Išvestis:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> The tokenizatorius.koduoti metodas prideda specialų [CLS] – klasifikacija ir [SEP] – separatorius žetonus užkoduotos sekos pradžioje ir pabaigoje.
BERT taikymas
BERT naudojamas:
- Teksto vaizdavimas: BERT naudojamas žodžių įterpimams arba žodžių sakinyje atvaizdavimui generuoti.
- Pavadinto subjekto atpažinimas (NER) : BERT galima tiksliai suderinti įvardintų objektų atpažinimo užduotis, kurių tikslas yra identifikuoti objektus, pvz., žmonių, organizacijų, vietovių pavadinimus ir kt. pateiktame tekste.
- Teksto klasifikacija: BERT plačiai naudojamas teksto klasifikavimo užduotims, įskaitant nuotaikų analizę, šiukšlių aptikimą ir temų skirstymą į kategorijas. Ji puikiai supranta ir klasifikuoja tekstinių duomenų kontekstą.
- Atsakymų į klausimus sistemos: BERT buvo pritaikyta atsakymų į klausimus sistemoms, kur modelis mokomas suprasti klausimo kontekstą ir pateikti atitinkamus atsakymus. Tai ypač naudinga atliekant tokias užduotis kaip skaitymo supratimas.
- Mašininis vertimas: BERT kontekstiniai įterpimai gali būti panaudoti tobulinant mašininio vertimo sistemas. Modelis fiksuoja kalbos niuansus, kurie yra labai svarbūs norint tiksliai išversti.
- Teksto santrauka: BERT gali būti naudojamas abstrakčiam teksto apibendrinimui, kai modelis generuoja glaustas ir prasmingas ilgesnių tekstų santraukas, suprasdamas kontekstą ir semantiką.
- Pokalbio AI: BERT naudojama kuriant pokalbio AI sistemas, tokias kaip pokalbių robotai, virtualūs asistentai ir dialogų sistemos. Dėl gebėjimo suvokti kontekstą jis veiksmingas suprantant ir generuojant natūralios kalbos atsakymus.
- Semantinis panašumas: BERT įterpimai gali būti naudojami sakinių ar dokumentų semantiniam panašumui įvertinti. Tai naudinga atliekant tokias užduotis kaip pasikartojančių duomenų aptikimas, parafrazės identifikavimas ir informacijos gavimas.
BERT prieš GPT
Skirtumas tarp BERT ir GPT yra toks:
| BERT | GPT | |
|---|---|---|
| Architektūra | BERT sukurtas dvikrypčio vaizdavimo mokymuisi. Jis naudoja užmaskuotą kalbos modelio tikslą, kai jis numato trūkstamus žodžius sakinyje, remdamasis kairiuoju ir dešiniuoju kontekstu. | Kita vertus, GPT yra sukurta generatyviniam kalbos modeliavimui. Jis nuspėja kitą sakinio žodį, atsižvelgiant į ankstesnį kontekstą, naudodamas vienakryptį autoregresinį metodą. |
| Išankstinio mokymo tikslai | BERT yra iš anksto apmokytas naudojant užmaskuoto kalbos modelio tikslą ir kito sakinio numatymą. Jame pagrindinis dėmesys skiriamas dvikrypčio konteksto fiksavimui ir žodžių santykiams sakinyje supratimui. | GPT yra iš anksto apmokytas nuspėti kitą sakinio žodį, o tai skatina modelį išmokti nuoseklaus kalbos vaizdavimo ir generuoti kontekstui svarbias sekas. |
| Konteksto supratimas | BERT yra veiksminga atliekant užduotis, kurioms reikalingas gilus konteksto ir sąsajų supratimas sakinyje, pvz., teksto klasifikavimas, įvardinto objekto atpažinimas ir atsakymas į klausimus. | GPT yra stipri kurdama nuoseklų ir kontekstą atitinkantį tekstą. Jis dažnai naudojamas atliekant kūrybines užduotis, dialogo sistemas ir užduotis, reikalaujančias sukurti natūralios kalbos sekas. |
| Užduočių tipai ir naudojimo atvejai
| Dažniausiai naudojamas atliekant tokias užduotis kaip teksto klasifikavimas, įvardytų objektų atpažinimas, nuotaikų analizė ir atsakymas į klausimus. | Taikoma tokioms užduotims kaip teksto generavimas, dialogų sistemos, apibendrinimas ir kūrybinis rašymas. |
| Tikslus derinimas prieš mokymąsi per mažai kadrų | BERT dažnai tiksliai derina konkrečias paskesnes užduotis su pažymėtais duomenimis, kad pritaikytų savo iš anksto parengtas reprezentacijas prie atliekamos užduoties. | GPT yra skirtas atlikti kelių kadrų mokymąsi, kai jis gali apibendrinti naujas užduotis su minimaliais konkrečios užduoties mokymo duomenimis. |
Taip pat patikrinkite:
- Sentimentų klasifikavimas naudojant BERT
- Kaip sugeneruoti Word įterpimą naudojant BERT?
- BART modelis automatiniam teksto užbaigimui NLP
- Toksiškų komentarų klasifikacija naudojant BERT
- Kito sakinio numatymas naudojant BERT
Dažnai užduodami klausimai (DUK)
K. Kam naudojamas BERT?
BERT naudojama atliekant NLP užduotis, pvz., teksto atvaizdavimą, įvardintų objektų atpažinimą, teksto klasifikavimą, klausimų ir atsakymų sistemas, mašininį vertimą, teksto apibendrinimą ir kt.
K. Kokie yra BERT modelio pranašumai?
BERT kalbos modelis išsiskiria dideliu išankstiniu mokymu keliomis kalbomis ir siūlo plačią kalbinę aprėptį, palyginti su kitais modeliais. Dėl to BERT ypač naudinga ne anglų kalba pagrįstiems projektams, nes ji suteikia tvirtą kontekstinį vaizdą ir semantinį supratimą įvairiomis kalbomis, padidindama jos universalumą daugiakalbėse programose.
K. Kaip BERT veikia atliekant nuotaikų analizę?
BERT puikiai atlieka nuotaikų analizę, panaudodama savo dvikrypčio vaizdavimo mokymąsi, kad užfiksuotų kontekstinius niuansus, semantines reikšmes ir sintaksines struktūras duotame tekste. Tai leidžia BERT suprasti sakinyje išreikštą nuotaiką, atsižvelgiant į žodžių ryšius, todėl nuotaikų analizės rezultatai yra labai veiksmingi.
amplitudės moduliacija
K. Ar „Google“ pagrįsta BERT?
BERT ir RankBrain yra „Google“ paieškos algoritmo komponentai, skirti apdoroti užklausas ir tinklalapių turinį, siekiant geriau suprasti ir pagerinti paieškos rezultatus.